Bijlage
Verdere uitwerking van punt 1: niet alle toestellen zijn ieder uur actief
De aanvaller wil de regio x van het toestel i bepalen.
- Van alle toestellen op i na is de regio bekend.
- Van toestel i weten we dat hij of in regio A zit of in regio B doordat we de locatie hebben van i in t-1 en t+1. We beperken ons hier dus tot twee mogelijke regio’s. Meer mogelijke regio’s maakt de locatie alleen maar onzekerder.
- We nemen een fractie f van de toestellen waar.
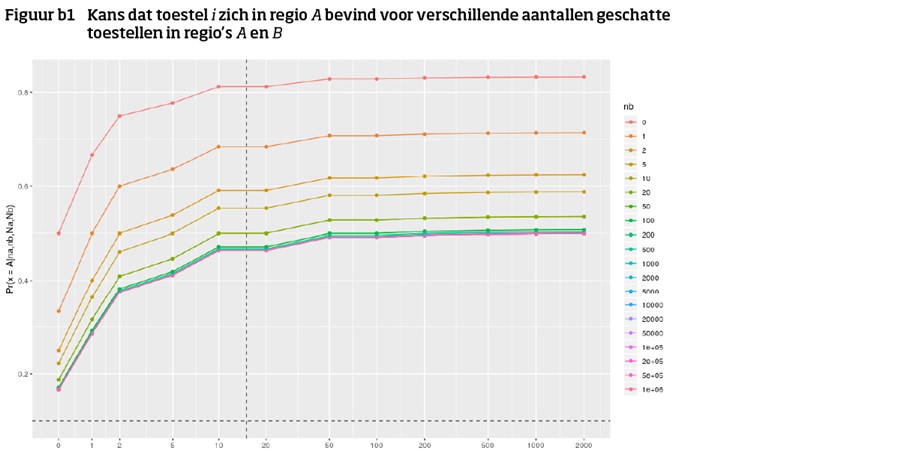
Gegeven de tellingen per regio, nA en nB, en de bekende aantallen per regio, NA en NB, wat is de kans dat device i in regio A zit en wat is de kan dat het device in regio B zit. De laatste volgt automatisch uit de eerste omdat het device of in A of in B zit.

De figuur hieronder geeft voor verschillende waardes van nA en nB de kans dat i in A zit. NA en NB zijn een factor 1/0.8 hoger gekozen dan nA en nB, de fractie f is gelijk aan 0.8. De verticale stippellijn geeft de grens aan waaronder de cijfers van een regio worden onderdrukt. De horizontale stippellijn geeft een kans van 0.1 aan: onder deze lijn weten we met 90% zekerheid dat i zich in regio B bevindt. Voor waardes van nA en nB groter dan 15, is iedere regio min of meer even waarschijnlijk, de data in de flowkubus geeft dus nauwelijks extra informatie over de locatie van het toestel.