4. Privacy
De Telecomwet vereist dat de gegevens die het telecombedrijf verlaten anoniem zijn. In dat kader is in een advies van de AP verwezen naar een wetenschappelijk artikel [2] dat een methode beschrijft om uit geaggregeerde telefoniedata de trajecten te herleiden van mobiele telefoons. In dit hoofdstuk wordt dieper op de in dit artikel beschreven methode ingegaan en wordt de vraag beantwoord in hoeverre dit gevolgen heeft voor de anonimiteit van de data.
Uitgangspunt is de dataset zoals deze vanaf de telefoonprovider geleverd wordt aan het CBS. Dit zijn geaggregeerde data met daarin geschatte tellingen hoeveel toestellen zich in een gegeven uur vanuit een gegeven woongemeente zich in een gegeven gemeente bevinden (de zogenaamde flowkubus). Dit hoofdstuk is als volgt ingedeeld:
- In paragraaf 4.1 wordt het inverse probleem uitgelegd en hoe dat in het proces veroorzaakt wordt. Daarmee wordt gekeken in hoeverre het technisch wiskundig mogelijk is om op basis van de laatste kennis, ondanks alle maatregelen rechtstreeks terug te rekenen tot een individu. Hierin wordt de anonimiteit wiskundig aangetoond. In dat kader is in een advies van de AP verwezen naar een wetenschappelijke artikelen [3] [4] uit China dat een methode beschrijft om uit geaggregeerde telefoniedata de trajecten te herleiden van mobiele telefoons. De in het artikel aangehaalde methode om uitkomsten te ‘’kraken” tot herleidbare uitkomsten is vrij nieuw maar loopt ook tegen dit inverse probleem aan. Het artikel beschrijft een complexe methode die de nodige wiskundige analyse vereist om deze goed te kunnen duiden. In paragraaf 4.1.3 wordt als aanvulling op de wiskundige benadering ook dieper op deze Chinese artikelen ingegaan en waarom deze niet kunnen werken op de methode die het CBS heeft gebruikt in de pilot.
- In paragraaf 4.2 wordt ingegaan op het hypothetisch geval waarbij aangenomen wordt dat de aanvaller (dit kan binnen het CBS zelf zijn, of een externe hacker met toegang tot data van bijvoorbeeld een “big tech” bedrijf) beschikt over een zeer grote hoeveelheid informatie (het meest extreme scenario) is het dan mogelijk om toch de locatie van het toestel van iemand te bepalen (d.m.v. een flowkubus)? Deze aanpak wordt in paragraaf 4.2 beschreven. Dit betreft een geavanceerde aanval die verder gaat dan het wetenschappelijk artikel uit China uit paragraaf 4.1.
- In paragraaf 4.3 wordt tenslotte het fenomeen groepsonthulling beschreven. Het betreft de mogelijkheid om groepen te kunnen identificeren uit de output data en welke waarborgen er worden genomen om het risico hierop zo veel mogelijk te beperken. Strikt genomen heeft dat niets met anonimiteit van het individu te maken. Het monitoren van groepen is juist een belangrijke toepassing voor de bestrijding van COVID. Toch is het belangrijk ook hier aandacht aan te besteden.
4.1 Wiskundige basisprincipes bij de anonimiteit van de CBS-methode
4.1.1 Het klassieke inverse probleem
Het wiskundige grondprincipe dat het CBS hanteert bij databeveiliging komt uit het vakgebied van algebra.
Wanneer een consistent systeem van onafhankelijke lineaire vergelijkingen over de reële getallen een kleiner aantal vergelijkingen heeft dan onbekenden, dan is de oplossingsverzameling oneindig groot.
Bijvoorbeeld als men een optelling doet van 5 getallen en alleen de som publiceert kan men onmogelijk de oorspronkelijke getallen achterhalen. Dit principe is de kern waarom de gegevens die door de mobiele telefoonbedrijven verstrekt worden anoniem zijn. Er kan dus wiskundig gezien niet worden teruggerekend, met welke methode of techniek dan ook.
De relatie tussen individuele objecten, zoals mobiele telefoons of vergelijkbare elektronische toestellen, en een meetgegeven als een telling van die objecten is een wiskundige vergelijking. De belangrijkste en onomkeerbare procedure in iedere deelstap van een verwerkingsproces is daarom om bewust bepaalde tellingen niet uit te voeren. Deze onomkeerbare informatievernietiging garandeert dat geen van de deelstappen omgedraaid kan worden om naar een individueel device te leiden. Dat geldt dus a fortiori voor het totale proces: van signalling data naar de geaggregeerde geanonimiseerde dataset die door het telecombedrijf wordt verstrekt aan het CBS.
4.1.2 Het inverse probleem dat ontstaat in het proces
Voor een precieze en volledige beschrijving van de processtappen wordt verwezen naar hoofdstuk 3 en de technische beschrijving [1]. In deze paragraaf wordt ingegaan op een aantal specifieke stappen die belangrijk zijn in het proces om te komen tot anonieme telefoondata.
1. Stap 1 t/m 6: De verwerking door het telecombedrijf (die plaatsvindt binnen de infrastructuur van het telecombedrijf)
Iedere 30 dagen worden alle gepseudonimeerde data bij de operator opnieuw gespeudonimiseerd waarbij er geen sleutel wordt gegenereerd (en dus ook niet bewaard kan worden). De dubbel gepseudonimiseerde data bevatten koppelingen tussen een mast en een device op een tijdstip van uitwisseling van een contactsignaal of data. De koppelingen tussen mast en device worden nog bewerkt. Daar zijn twee redenen voor:
- Een inhoudelijke reden. Tussen welke antenne en device er op een tijdstip een koppeling wordt gemaakt, is niet uitsluitend afhankelijk van fysieke nabijheid, maar hangt ook af van signaalsterkte die niet uniform is rond een antenne, en beschikbaarheid van verwerkingscapaciteit van signalen door de antenne. Binnen een tijdsinterval van een uur wisselen toestellen vaak en in willekeurige volgorde met meerdere masten signalen uit. Het is daarom statistisch meer zuiver om ieder van de individuele mast-device koppelingen gewogen te verdelen over een aantal masten.
- Een beveiligingsreden. Doordat koppelingen opgedeeld worden over een aantal antennes, en vervolgens aantallen fractionele koppelingen op te tellen per mast wordt de 1-op-1 relatie tussen een individuele mast en device onherstelbaar verstoord.
De optelling per mast moet altijd gewogen worden verdeeld over gemeenten, omdat het gevoeligheidsgebied van iedere mast meerdere gemeenten bestrijkt. Voor deze data geldt dus dat er geen unieke, omkeerbare, relatie bestaat tussen de tellingen per gebied of mast en de aantallen betrokken toestellen per gebied of mast: er zijn meer onbekenden dan er meetgegevens zijn en dus geldt het wiskundige grondprincipe dat de onbekenden niet meer kunnen worden bepaald. Er is bewust informatie vernietigd om identificatie te voorkomen. In hoofdstuk 3 staat de exacte werking van het algoritme van de locatietelling vermeld als volgt:
- “….De locatie is dus niet heel precies: er wordt in deze stap statistische ruis toegevoegd. Een bijkomend effect van deze methode is dat aantallen toestellen worden “verspreid” in de ruimte en daarmee worden herverdeeld. Ook in de tijd is er sprake van een verspreiding. Het model werkt in een batch van een uur. Als er maar één meting is in een specifiek uur dan worden deze gegevens geëxtrapoleerd over andere minuten binnen dat uur. Er vindt geen spreiding plaats tussen de uren als tijdseenheid. De verspreiding in ruimte en tijd veroorzaakt een extra ruis die elk uur verandert van samenstelling. Dit betekent dat de relatie tussen de tellingen per gebied en de tellingen per mast een systeem van lineaire vergelijkingen is, met minder vergelijkingen dan onbekenden en daarom niet uniek inverteerbaar.
- We illustreren dit met een voorbeeld. Stel dat we voor een toestel met nummer 1 in het uur 8:00—9.00 over gemeenten A, B en C de respectievelijke kansen 0,5, 0,3 en 0,2 verkrijgen. We achtten de kans dus groter dat het toestel zich in gemeente A bevond, maar laten deze kansverdeling zoals hij is – wij kennen hem niet definitief toe aan A. Stel dat wij verder voor een ander toestel 2 in hetzelfde uur een kansverdeling over gemeente A, B en C deze op 0, 1, en 0 schatten. Oftewel, wij vermoeden dat het toestel zich in dat uur volledig in gemeente B bevond. Dan tellen wij de kansverdelingen voor beide toestellen op: 0,5, 1,3 en 0,2. Wij schatten dus dat zich 1,3 toestellen in gemeente B bevonden.”
Aanvullend dient gemeld te worden dat het bereik van antennes sterk varieert, van 5 meter tot 60 kilometer over gemeentegrenzen heen. Ook de hoek kan variëren van 2 graden tot 360 graden. Zoals voorgeschreven hanteert het telecombedrijf de regel dat wanneer de tellingen in een bepaald gebied binnen een bepaald tijdvak onder de ondergrens van 15 vallen, die data onderdrukt en daarmee vernietigd wordt. Het totale aantal toestellen per tijdsinterval in de uiteindelijke dataset die naar het CBS komt fluctueert sterk. Immers, als een toestel in een uur geen verbinding heeft gemaakt met het netwerk voor een telefoongesprek of sms bestaat voor dat toestel geen registratie voor dat uur, en wordt dat toestel in dat uur niet meegeteld in de dataset die aan het CBS wordt verstrekt. De populatie is dus niet constant in grootte en al helemaal niet in samenstelling. De fluctuaties worden nog versterkt door de onderdrukking van kleine tellingen zoals hierboven genoemd. Het is belangrijk dit hier te vermelden omdat het voor bijvoorbeeld het paper[3] een essentiële vereiste is dat de populatie van toestellen constant is in samenstelling en grootte.
Bij binnenkomst van deze tabellen bij het CBS zijn er dus verschillende onomkeerbare handelingen verricht die informatie vernietigd hebben, zodat er zelfs met de data en resources die het CBS zelf ter beschikking heeft geen identificatie meer mogelijk is. De data die het CBS ontvangt zijn dus anoniem.
Stappen 7-9 Statistische output
Het aantal verschillende tellingen dat wordt gemaakt (per gemeente) heeft een ingewikkelde en niet omkeerbare relatie met de aantallen getelde toestellen. Het aantal onbekenden is weer groter dan het aantal vergelijkingen: de tellingen op gemeenteniveau. De “standaard” CBS statistische beveiliging voor CBS publicaties wordt hier nogmaals toegepast. Als extra maatregel zijn de te publiceren aantallen aangepast naar relatieve waarden. Er wordt dus in deze stap opnieuw en bewust informatie vernietigd om het onmogelijk te maken voor een externe partij om zelfs maar tellingen per mast te reconstrueren, laat staan om bewegingen van individuen te herleiden.
4.1.3 Bespreking academische publicaties
Op basis van wat in 4.1.1 en 4.1.2 beschreven is identificatie onmogelijk omdat dit een schending is van de genoemde wiskundige grondprincipe. Behalve het in de inleiding geciteerde paper[3] zijn er ook andere papers[4],[5] gepubliceerd waarin technieken worden besproken die zich erop richten om uit het pad dat een device volgt iets te kunnen onthullen over de drager of eigenaar van dat device. Er is beduidende academische interesse in dit onderwerp en er zijn dus veel meer papers op dit gebied die al gepubliceerd zijn of gepubliceerd zullen worden. Het is niet haalbaar om alle bestaande literatuur op dit gebied individueel te bespreken.
Echter, al dergelijke methoden moeten, om te kunnen werken, toegepast kunnen worden op data in een proces waar het eerder genoemde wiskundige grondprincipe expliciet of impliciet niet van toepassing is. Met andere woorden, direct terugrekenen om te onthullen kan niet. Deze papers zijn veelal gericht op benadering van het individu met een zekere waarschijnlijkheid.
De meeste methoden blijken niet toepasbaar op uitkomsten zoals die volgens de hiervoor beschreven werkwijze tot stand komen. Het ontwerp van de methode maakt een aantal kraakmethoden daardoor niet toepasbaar. In een deel van de gepubliceerde papers wordt aangenomen dat er ‘tracks’ beschikbaar zijn waarin de opeenvolgende masten waarmee toestellen in contact treden worden opgeslagen en als geheel verwerkt.
De fundamentele aanname voor die methodes is dat de 1-op-1 relatie tussen device en mast of gebied dus behouden blijft. Dit is in strijd met de door de telecomaanbieder in stap 1 (en stap 3) gehanteerde methode. De conclusies van elk paper dat gebruik maakt van dergelijke tracks kunnen daarom niet toegepast worden op de methode die door het CBS wordt gebruikt. De module MobLoc is hiervoor essentieel. Daarnaast blijft het noodzakelijk voor dit soort methoden om externe individueel identificerende informatie te gebruiken zodat een bepaald track van een device aan een persoon verbonden kan worden.
De door de CBS-methode gegenereerde data is van een heel ander type dan de data in het paper [3]. De belangrijkste aanname in het paper [1] is dat in opeenvolgende tijdsintervallen er identiek 1-op-1 dezelfde toestellen in de dataset zitten, waar bovendien ieder device 1-op-1 aan een mast gekoppeld is. Het 1-op-1 gekoppeld zijn van mast en device wordt in stap 1 van het hierboven besproken proces expliciet voorkomen.
Het is onduidelijk of de in het paper beschreven procedure überhaupt hierop aan te passen is. Hiervoor is aanvullend onderzoek nodig. In dit artikel wordt een relaxatie voor het algoritme toegepast op basis van een aantal aannames om de berekening mogelijk te maken. Het is waarschijnlijk dat een relaxatie voor de situatie met miljoenen toestellen die moet leiden tot een aanvaardbare rekentijd zal leiden tot een verlaging van de nauwkeurigheid waardoor er meer “onjuiste” routes gevonden zullen worden. Ook al is de rekenkracht aanwezig, dan nog kan de gewenste nauwkeurigheid die moet leiden tot identificatie niet bereikt worden.
Het eerstgenoemde paper[3] gebruikt ook tracks, maar neemt die niet als startpunt. In plaats daarvan worden tellingen per mast in opeenvolgende tijdsintervallen aan elkaar gekoppeld zodat tracks geconstrueerd kunnen worden. Hierbij worden modelaannames gebruikt voor typische bewegingen van toestellen (patronen). Immers, van verplaatsingsgedrag is bekend dat mensen vaak dezelfde patronen hebben. Om dit probleem op te lossen wordt het zogenaamde ‘Hongaars algoritme’ gebruikt. Er zijn meerdere aannames inherent aan de methode zoals beschreven in dat paper, waardoor de conclusies niet van toepassing kunnen zijn op de processtappen die zijn gevolgd door het CBS. Het aantal toestellen in het paper[3] is vele malen kleiner dan bij de data op grond van de analyses die in het kader van pilot voor het betaproduct zijn gedaan (100 duizend versus 21 miljoen) terwijl het aantal locaties waarvoor aggregaten bepaald worden in dat paper vele malen groter is dan de data (uitsluitend op gemeenteniveau) die aan het CBS zal worden verstrekt (8,600 versus 400). Het verschil tussen het aantal vergelijkingen en het aantal onbekenden is daarom voor de data die aan het CBS wordt verstrekt nog vele malen groter dan het geval is in het paper. Dat zou neerkomen op een orde van grootte van 1*1018. Dat maakt de verwerking van deze procedure met de huidige beschikbare computerkracht van het CBS onmogelijk. Zover bekend is het uitvoeren van de in het artikel beschreven procedure op een dergelijke dataset slechts door een viertal supercomputers in de wereld mogelijk (exa-scale computing).
Laten we kijken naar het volgende gedachtenexperiment behorende bij de kraakmethode uit het artikel van Tu [3] Daarbij nemen we voor het gemak even aan dat een toestel zich gedurende een uur slechts in één gemeente kan bevinden2). Beschouw de werkelijke trajecten van twee toestellen met dezelfde thuisgemeente, en wijzig deze door voor een bepaald uur de twee gemeentes in hun trajecten [3] te verwisselen. Dan zijn de geaggregeerde flowkubussen3) voor en na de verwisseling identiek. Dit eenvoudige voorbeeld toont al aan dat meerdere trajectendatasets na aggregatie tot dezelfde flowkubus kunnen leiden. Uit dit argument is echter niet op te maken of, en in welke mate de flowkubus kan bijdragen aan identificatie van individuen. Het zou namelijk kunnen dat sommige combinaties van paden plausibeler zijn dan andere. Deze plausibiliteitsinformatie zou een aanvaller kunnen toevoegen aan het probleem om een betere schatting van de oorspronkelijke paden te maken. Dus stel dat een aanvaller beschikt over extra data (zoals algemene mobiliteitspatronen, of data van een specifiek individu) naast de flowkubus. In hoeverre is het dan mogelijk om delen van de vergelijkingen toch op te lossen?
De aanname dat alle toestellen op ieder moment in de data aanwezig zijn is een geïdealiseerde situatie die in echte datasets, zoals de aan het CBS te verstrekken dataset, niet optreedt. Dit is echter wel cruciaal voor het Hongaars algoritme (een optimalisatiemethode) als in [3] beschreven om te kunnen werken. Zodra er zelfs maar 1 device in een tijdsinterval verdwijnt of verschijnt kan dat algoritme niet geoperationaliseerd worden. In het paper[3] worden daarom toestellen geheel weg gelaten uit de populatie of wordt er geïnterpoleerd. De in het paper[3] beschreven academische methode is om die reden niet toepasbaar op de dataset die het CBS in de pilot heeft verwerkt.
Ook wordt in het paper[3] aangegeven dat extra informatie nodig is om een gereconstrueerd traject aan een herkenbaar individu te koppelen. In het paper is een gereconstrueerd traject “unique” als het op basis van n toplocaties te koppelen is aan een uniek traject binnen de “ground truth”. Vervolgens wordt er van uit gegaan dat een uniek traject binnen de “ground truth” aan een uniek persoon in de populatie te koppelen is. Voor die laatste stap is dus extra informatie nodig, die ook nog eens uniek aan een herkenbaar persoon gekoppeld moet kunnen worden.
In het algemeen kan gesteld worden dat ieder algoritme of methode dat een uniek device kan identificeren, er vanuit moet gaan dat iedere stap in het verwerkingsproces van de ruwe telecomdata uniek inverteerbaar is. Het wiskundige grondprincipe zorgt er juist voor dat iedere verwerkingsstap niet inverteerbaar is, en onthulling dus niet slechts onwaarschijnlijk of zeer rekenintensief, maar wiskundig onmogelijk is. De vervolgvraag is dan of een aanvaller met extra informatie toch niet de waarheid kan benaderen. In paragraaf 4.2 wordt hier dieper op in gegaan d.m.v. een ander extreem aanvalsscenario.
Voor de volledigheid zijn er nog onderstaande overige kritische punten bij dit artikel [3]:
- Door uit te gaan van een N>15 vervallen alle unieke routes die men snel zou kunnen samenstellen op basis van lage aantallen uit de data.
Hoe uniek een route is wordt in het artikel niet genoemd, het beschrijft alleen hoe groot het percentage gevonden unieke trajecten is op basis van de TopK (meest bezochte) locaties “…uniqueness measures the possibility that he can uniquely distinguish victims' recovered trajectories. Therefore, we define the uniqueness as the percentage of recovered trajectories that can be uniquely distinguished by their most frequent k locations (Top-K)”. Vervolgens is externe informatie nodig om dat gevonden traject te koppelen aan een individu; “Therefore, the results indicate that the recovered trajectories are very unique and vulnerable to be reidentified with little external information.” Welke externe informatie nodig is, wordt niet genoemd, maar het is aannemelijk dat ze bedoelen dat je weet welke TopK locaties bij een persoon horen. Of het daadwerkelijk de juiste persoon is (is die persoon de enige met die TopK locaties) wordt niet bekeken, omdat men aanneemt dat een persoon/toestel kan worden geïdentificeerd door een unieke TopK . Dus een persoon met een TopK aantal locaties klopt met de route, maar dat mag je niet omkeren naar de opmerking dat je die aan een uniek persoon kunt koppelen. Juist ook omdat in de hoofdstuk 3 beschreven methoden de gebieden erg groot zijn (en geen cellen). De vraag is dan ook of die koppeling de juiste is. - In de studie worden cellen (“area covered by base station”) gebruikt als geografische afbakening. Wij gebruiken gemeenten in plaats van gebiedscellen. Dat maakt de koppeling van een route aan een toestel veel moeilijker. In het artikel wordt gesproken over 8.000 base stations. Dit betekent dat er 511.808.016.000 unieke varianten van een top 3 van meest bezochte base stations mogelijk zijn. In onze dataset met 355 gemeenten zijn er 44.361.510 unieke varianten van een top 3 van meest bezochte gemeenten van elk persoon. Dit is een factor van ongeveer 11.500 lager om een top 3 aan een toestel te koppelen. Het kleinere aantal unieke varianten van een top 3 wordt in ons geval ook nog eens over 2 tot 4 miljoen toestellen verdeeld in plaats van over 100 duizend toestellen. Daarmee wordt de “uniciteit” van een top 3 combinatie (“being different from others” in het artikel genoemd) 200.000 tot 400.000 keer zo klein.
De "recovery accuracy" zal vele malen lager zijn doordat niet 100.000 maar 4 miljoen devices in de dataset zitten (zie figuur 11 a voor afname accuracy bij toename van aantal toestellen). Daardoor is de kans groot dat indien een traject met de correcte TopK locaties aan een persoon gekoppeld kan worden de route niet juist is. Daarmee wordt de kennis over die persoon dus niet verrijkt.
4.2 Aanvalsscenario
In paragraaf 4.1 is aangetoond dat het oplossen van vergelijkingen niet werkt om tot onthulling te komen. Wat als iemand, een aanvaller of hacker over extra aanvullende informatiebronnen kan beschikken? Wat zijn dan de gevolgen? Stel, de aanvaller weet voor een bepaalde afgeleide herkomstgemeente van alle toestellen van een telecombedrijf op één na waar ze zijn gedurende periode t (van één uur). In de periodes daarvoor en daarna weet de aanvaller ook van dit ene toestel waar het is. Het doel van de aanvaller is om te weten te komen waar het toestel gedurende periode t was. De aanvaller weet de locatie van het device in t-1 en in t+1, en gezien de maximale reissnelheid van het toestel blijven er een aantal regio’s over waarin het toestel in de tussentijd geweest kan zijn. De vraag is nu in hoeverre de flowkubus de aanvaller kan helpen met dit probleem. Laten we aannemen dat er op tijdstip t sprake is van meer dan één mogelijke regio aangezien de aanvaller anders de flowkubus sowieso niet nodig heeft. Die data onthult dan niets wat de aanvaller al niet wist.
Aangezien de aanvaller de locaties van alle andere toestellen weet zou de locatie simpel te vinden moeten zijn: hij neemt de aantallen uit de flowkubus; trekt de bekende aantallen ervan af en als het goed is, is er één regio over waar een verschil van één overblijft. Er zijn echter een aantal eigenschappen van de signalling data en de methodologie waarmee de flowkubus is geproduceerd waardoor deze rekensom veel lastiger is om te maken dan men in eerste instantie zou denken. Dit heeft de volgende oorzaken:
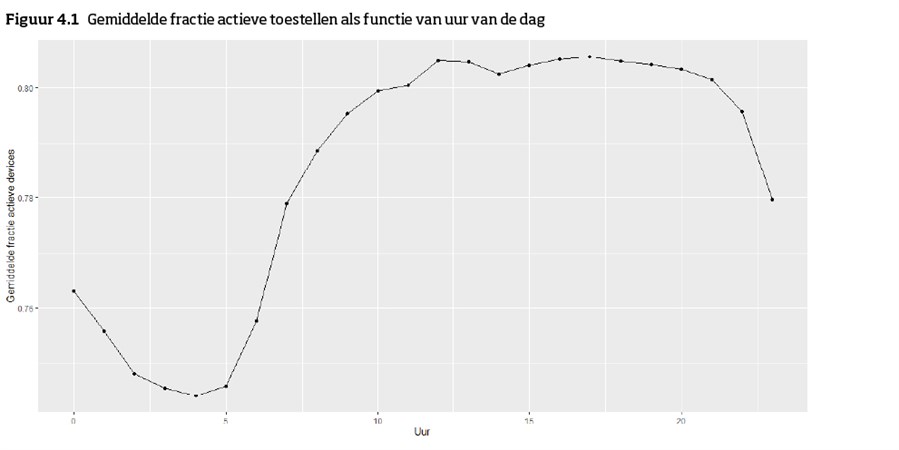
- Niet alle toestellen zijn altijd actief. Dus hoewel de locaties van alle toestellen te achterhalen zijn op basis van de brondataset, is niet bekend welke daarvan ook daadwerkelijk actief waren gedurende periode t. Voor de zekerheid wordt aangenomen dat het toestel waarvan de locatie gezocht wordt wel actief was en dat dat bekend is bij de aanvaller. Zoals in figuur 4.1 te zien is, is gedurende de dag per uur circa 20-25 procent van de toestellen niet actief. Gemiddeld is 78% om 7:00 in de ochtend actief.
- De aanvaller weet waar de apparaten zich bevinden, maar weet niet zeker aan welk gebied deapparaten zijn toegewezen. Toewijzing van apparaten aan gebieden gebeurt via de zendmast4). Voor veel zendmasten geldt dat ze in meerdere gebieden dekking bieden. Met behulp van een model wordt voor een gegeven zendmast één toestel verdeeld over alle gebieden waar de zendmast dekking geeft (de fracties tellen op tot één). Het is de aanvaller ook niet bekend met welke zendmast een toestel verbonden is geweest (als hij al verbonden was; zie vorig punt).
Voor veel zendmasten geldt dat een connectie met deze zendmast vervolgens ook niet 1 op 1 vertaald kan worden naar een gemeente. Dus zelfs als de aanvaller gegevens heeft over de werkelijke locatie van elk toestel, bestaat er onzekerheid over in welke gemeente dit toestel wordt opgenomen door de schattingsmethode. Wanneer een zendmast meerdere gemeenten bedient dan wordt een toestel in gewogen fracties meegeteld in alle gebieden waar de zendmast dekking geeft. Een waarde van 100 toestellen in de data kan bijvoorbeeld dus bestaan uit 200 maal een bijdrage van 0.5.
Van regio’s waarin minder dan 15 toestellen geschat worden is de waarde niet aanwezig in de flowkubus. Er zijn dus heel veel regio’s waarvoor de som sowieso niet uitgerekend kan worden. Het aantal cellen dat wordt onderdrukt is wel sterk tijdstip afhankelijk. ’s Nachts gaat het om veel meer tabelcellen maar wel veel minder toestellen en vice versa.
Ieder van bovenstaande punten maakt het onmogelijk voor de aanvaller om de locatie van het toestel met redelijke zekerheid te bepalen. Stel er worden in een regio 0 (nul) toestellen geschat. Circa 80% van de toestellen wordt waargenomen. Het aantal waargenomen toestellen zal daarom een binomiale verdeling volgen (met p = 0.8). Dit betekent dat er met 90% waarschijnlijkheid zich ook één toestel in die regio kan bevinden. Als er meer toestellen worden geschat wordt het waarschijnlijkheidsinterval alleen nog maar groter. Bij 10 waargenomen toestellen, kunnen er zich in werkelijkheid tot 16 toestellen in de regio bevinden. Aangezien de onzekerheid in het aantal werkelijke toestellen in de regio al groter of gelijk is aan één wordt de locatie bepalen van het ene toestel erg lastig. Dit voorbeeld wordt in bijlage 1 verder uitgewerkt aangezien de bekende aantallen toestellen wel extra informatie geven.
Het effect van punt 2 varieert ook sterk per gebied. In stedelijk gebied zijn veel meer zendmasten waardoor zendmasten minder vaak een groot gebied bestrijken terwijl in landelijk gebied de masten vaak grotere gebieden bestrijken. Ook als veel zendmasten overlappen in dekkingsgebied wordt dit probleem complexer. Exacte cijfers hierover zijn op dit moment echter niet beschikbaar.Zoals in punt 3 wordt aangegeven, worden voor veel regio’s de cijfers onderdrukt. Over deze regio’s is niets bekend anders dan dat het aantal geschatte toestellen kleiner is dan 15.
4.3 Groepsonthulling en nuancering van de N>15 regel bij stap 6
De output die het telecombedrijf levert bevat een tabel waarvan alle cellen meer dan 15 geschatte toestellen bevatten. Het is belangrijk te realiseren dat dit geen echte directe tellingen zijn. Het is een uitkomst van een Baysiaanse schatting. Dus zelfs een uitkomst van één toestel is in werkelijkheid niet uniek en daarmee anoniem. Als er een identificatie plaatsvindt dan is dat puur op basis van toeval en is een onthuller er dus ook niet zeker van. Echter, ook onterechte (maar als juist geïnterpreteerde) onthulling is onwenselijk; vandaar dat er wel een ondergrens is gesteld. Dat is de voornaamste reden voor deze grens.
Het denkvoorbeeld is een bus studenten die tussen 2:00 en 3:00 uur van de gemeente Groningen naar een andere gemeente gaat. Als er tussen deze studenten meer dan 15 dezelfde provider hebben en deze groep van studenten allemaal in eenzelfde uur in een zelfde gemeente actief zijn (er zijn events van die toestellen) en toevallig door het geolocatiealgoritme in dezelfde gemeente worden toegewezen én er is geen enkele andere beweging van toestellen met dezelfde herkomstgemeente Groningen naar die gemeente dan kan een dergelijke groep herkend worden in de aan het CBS geleverde data.
Dat lijkt op onthulling, maar in feite wist men dat men op zoek moest gaan naar deze groep. Agenda informatie (bijvoorbeeld een programmapublicatie op het internet) was noodzakelijk. Er is dus uit deze databron geen extra informatie onthuld in dit geval, wel is er sprake van een eenmalige herkenning (of validatie) van de uitkomsten. Ook kan men binnen die groep geen individuen herkennen. Wel kan men aan die groep bepaalde kenmerken toevoegen zoals dat deze via een andere gemeente is gereisd.
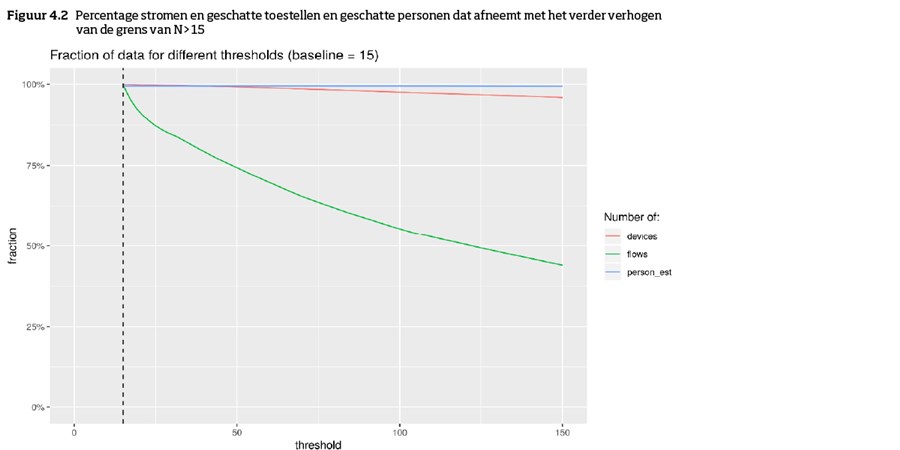
Bij een hogere grens N zou de kans op groepsherleiding nóg kleiner worden, maar dat geldt dan alleen binnen de infrastructuur van het CBS. De grens van N>15 is echter nauwkeurig onderzocht. Daarbij is er gestreefd naar data-minimalisatie in relatie tot de toepassing: de data moeten wel bruikbaar blijven. Figuur 4 en 5 laten zien dat het verder verhogen van de grens in stap 6 leidt tot uiteindelijk uitkomsten die onbruikbaar zijn. In figuur 4.2 is te zien dat de dynamiek/stromen van de bevolking tussen verplaatsingen van gebieden (groene lijn) sterk verdwijnt bij het verhogen van de grens/”treshold”, terwijl die informatie juist relevant is voor het maken van statistiek.
Wetende dat er onder zeer uitzonderlijke omstandigheden een risico op groepsherleiding kan bestaan zijn er diverse waarborgen genomen om te voorkomen dat deze informatie zou worden gebruikt om groepen personen te identificeren in de data die aan het CBS worden geleverd. Wettelijk is het voor het telefoonbedrijf verboden om herleidbare gegevens van individuen te verstrekken en voor het CBS is het wettelijk verboden om herleidbare gegevens openbaar te maken. Dit verbod wordt ook met organisatorische en technische maatregelen ondersteund. Zo is de toegang tot deze data bij het CBS afgeschermd en kunnen slechts enkele medewerkers van het CBS bij deze data.
3) In het wetenschappelijk artikel worden trajecten samengesteld uit de data. De in de pilot gebruikte methode kan niet gebruikt worden om routes samen te stellen, maar er kan aangenomen worden dat uit de tellingen per uur misschien een route kan worden samengesteld.
4) Hiermee wordt een woonplaats bestemmingstabel bedoeld met daarin tellingen in de tijd. Bijvoorbeeld in Amsterdam zijn om 12:00 uur 300.000 mensen uit Amsterdam en 500.000 mensen uit omliggende gemeenten. Door de uren naast elkaar te leggen kan men in de tellingen de “stromen”/ “flow” waarnemen. De derde dimensie is dan de tijd, vandaar de naam flowkubus, een herkomstbestemmingsmatrix in de tijd.
5) Dus de aanvaller weet wel de locaties van alle andere toestellen, maar dat aftrekken van de flowkubus aantallen zal verkeerde (en mogelijk negatieve) getallen opleveren. Dus de aanvaller zou ook moeten weten welke andere toestellen allemaal actief waren.