2. Methoden en data
Het doel van de herijking is het bepalen in welke mate de omgevingskenmerken uit de po-indicator samenhangen met de schoolprestatie van leerlingen in het primair onderwijs. Het relatieve belang van de diverse kenmerken wordt opnieuw geschat met behulp van geactualiseerde data.
2.1 Methoden voor herijking
Structurele vergelijkingsmodellen
Om onderwijsprestaties zo goed mogelijk te kunnen verklaren is het belangrijk dat een geschikt analysemodel gekozen wordt. In dit onderzoek ontwikkelen we een model waarbij we – net als bij de ontwikkeling van de huidige indicator – corrigeren voor intelligentie. Hiervoor zullen we gebruik maken van structurele vergelijkingsmodellen (Bollen, 1989). Met structurele vergelijkingsmodellen is het mogelijk om onderscheid te maken tussen enerzijds directe effecten van achtergrondvariabelen op schoolprestatie en anderzijds indirecte effecten die via intelligentie lopen. Dit is van belang omdat we uiteindelijk onderwijsachterstanden, oftewel voor intelligentie gecorrigeerde schoolprestaties, willen verklaren. Het doel is om de directe effecten van de overige achtergrondvariabelen (exclusief intelligentie) zo goed mogelijk te kunnen schatten. Hiervoor is het noodzakelijk om ook de indirecte effecten via intelligentie te modelleren. Om rekening te houden met niet-normaliteit en clustering op schoolniveau hebben we de structurele vergelijkingsmodellen geschat met behulp van pseudo maximum likelihood.
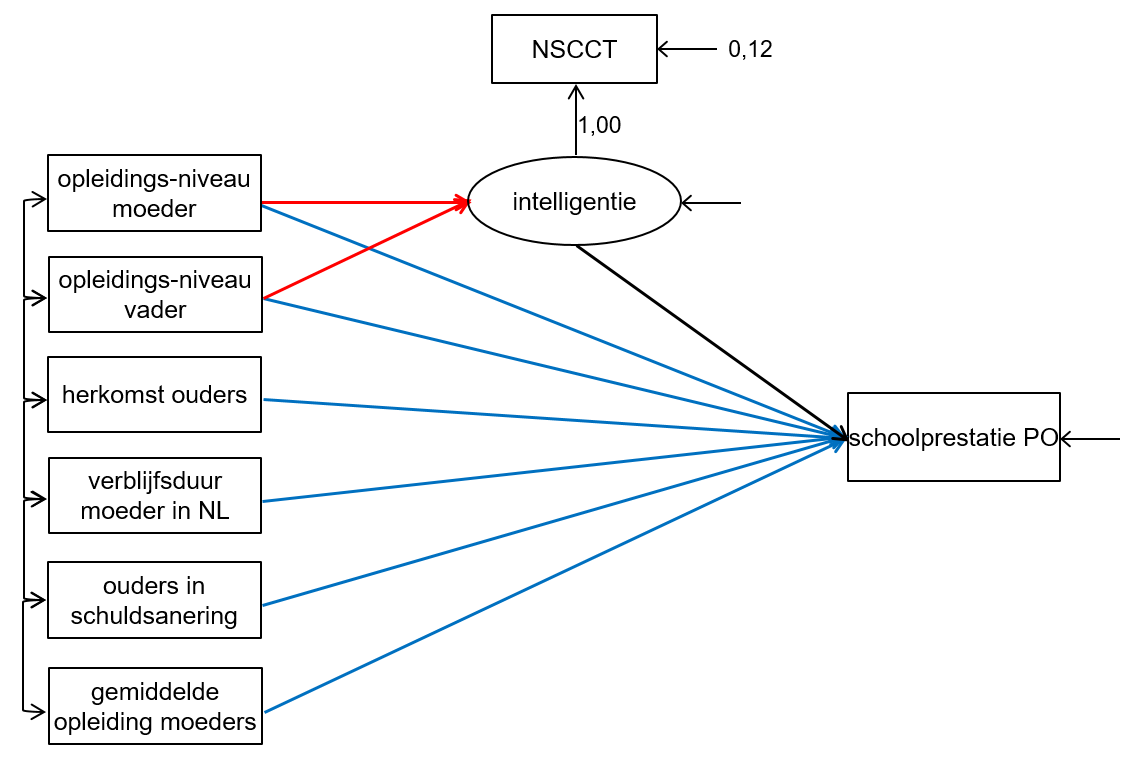
Figuur 2.1.1 geeft schematisch het model van de huidige po-indicator weer. De directe effecten van de omgevingskenmerken worden weergegeven door de blauwe pijlen in de figuur en de indirecte effecten van het opleidingsniveau van beide ouders worden weergegeven door de rode pijlen. In dit onderzoek bekijken we ook of het zinvol is om ook voor de andere omgevingskenmerken indirecte effecten op te nemen in het model. Bij het bepalen of een toevoeging van een indirect effect zinvol is, hebben we gekeken naar twee aspecten. Ten eerste is gekeken of er een theoretische grondslag is voor het toevoegen van zo’n effect. Ten tweede hebben we ook gekeken of de uitkomsten van de modellen aanleiding gaven tot het toevoegen van één of meerdere extra indirecte effecten.
In de indicator voor onderwijsachterstanden in het po worden uiteindelijk alleen de blauwe pijlen meegenomen: dit zijn namelijk de effecten van omgevingskenmerken die verklaren dat leerlingen met dezelfde aanleg (intelligentie) maar een andere omgeving gemiddeld verschillend presteren. Nadelige directe effecten van omgevingskenmerken leiden zo tot onderwijsachterstanden. Een uitgebreide toelichting op het gebruikte model is te vinden in het eerste methodologische rapport van de po-indicator.
2.1.1 Schematische weergave structureel vergelijkingsmodel
Modelselectie
Om de verschillende structurele vergelijkingsmodellen met elkaar te kunnen vergelijken, gebruiken we het Akaike Informatie Criterium (AIC) en het Bayesiaanse Informatie Criterium (BIC) als primaire fitmaten. Een lagere AIC- of BIC-waarde wijst daarbij op een betere modelfit. Enerzijds zorgt het toevoegen van meer verklarende variabelen ervoor dat de waarde van het AIC of BIC daalt. Anderzijds neemt bij het toevoegen van variabelen de kans op overfitten toe. De AIC en BIC houden rekening met deze kans op overfitten via een positieve term die toeneemt met het aantal parameters in het model, zodat complexere modellen in het nadeel zijn. Deze ‘penalty-term’ is (gezien de steekproefomvang van de data die we hier gebruiken) groter bij het BIC dan bij het AIC. Naast de AIC en BIC kijken we ook naar de verklaarde variantie in schoolprestaties. De aangepaste R-kwadraat meet de fractie verklaarde variantie, rekening houdend met de complexiteit van het model.
Verder hebben we, om de volgorde te bepalen waarin mogelijke extra indirecte effecten worden toegevoegd aan het model uit figuur 2.1.1, gebruik gemaakt van zogenaamde modificatie-indices. Bij een gegeven structureel vergelijkingsmodel kan voor elk potentieel effect dat niet is opgenomen in het model een modificatie-index worden berekend die een schatting geeft van de verbetering in de modelfit (zoals gemeten door het AIC of BIC zonder penaltyterm) die op zou treden als dit effect wordt toegevoegd aan het model. Eventuele extra indirecte effecten voegen we aan het model toe op volgorde van de hoogte van de modificatie-index waarbij we het indirecte effect met de hoogste modificatie-index als eerste toevoegen.
Stapsgewijze aanpak
Voor het ontwikkelen van een geactualiseerd model voor de onderwijsachterstandenindicator hebben we een stapsgewijze aanpak gebruikt. Hierbij zal eerst een model worden geschat op basis van de grotere steekproef waaraan de leerlingen uit het derde COOL5-18-onderzoek zijn toegevoegd, met dezelfde directe en indirecte effecten als bij de huidige indicator (het basismodel uit figuur 2.1.1). Vervolgens zal een aantal modellen worden geschat waarin stapsgewijs meer indirecte effecten worden opgenomen onder de voorwaarde dat een dergelijke toevoeging ook zinvol is.
Ten opzichte van de huidige po-indicator hebben we een tweetal verbeteringen doorgevoerd in het basismodel. De eerste verbetering betreft het schatten van het gemiddelde opleidingsniveau van de moeders op een school. Bij het toewijzen van een waarde per school voor het gemiddelde opleidingsniveaus van alle moeders gebruiken we nu de eerder bepaalde schaalwaarden van de opleidingsniveaus van de moeders. Bij de ontwikkeling van de huidige po-indicator werden de schaalwaarden van opleidingsniveau moeder hiervoor opnieuw bepaald via een apart regressiemodel op een grotere dataset. Dit laatste was bij nader inzien niet logisch, omdat later bij het toepassen van de indicator de bijdrage van gemiddeld opleidingsniveau per school wordt berekend op basis van de schaalwaarden die zijn bepaald voor de opleidingsniveaus van de moeders. Het is dan ook logischer om bij het schatten van het model niet uit te gaan van een aparte schatting van de schaalwaarden voor het opleidingsniveau van de moeders ten behoeve van het bepalen van het gemiddelde opleidingsniveau van de moeders op een school. Dezelfde aanpak is ook gevolgd bij het schatten van de andere modellen.
De tweede verbetering betreft het aantal keer dat een specifiek model is geschat. Bij de ontwikkeling van de huidige po-indicator is gebruik gemaakt van één opleidingsniveau variabele per ouder. Deze variabelen bevatten zowel bekende als geïmputeerde opleidingsniveaus. Uit eerder onderzoek (Scholtus en Pannekoek, 2015) weten we dat er een bepaalde onzekerheid zit in de imputaties van het opleidingsniveau. Voor de achtergrondkenmerken hebben we daarom voor beide ouders het opleidingsniveau vijf keer geïmputeerd. Als het opleidingsniveau van een ouder bekend is, zijn deze vijf waarden allemaal gelijk aan de bekende waarde; bij ouders met een onbekend opleidingsniveau variëren de geïmputeerde waarden. Vervolgens hebben we ook ieder model vijf keer geschat en de uitkomsten – fitmaten, modelcoëfficiënten en schaalwaarden– gemiddeld. De standaardfouten en p-waarden van de geschatte coëfficiënten zijn bepaald met behulp van de formules van Rubin (1987) voor multipele imputatie. Op deze wijze wordt de inherente onzekerheid bij het imputeren van het opleidingsniveau in ieder geval gedeeltelijk gecompenseerd.
Analyse effecten op school- en gemeenteniveau
Omdat de onderwijsachterstandsgelden op school- en gemeenteniveau worden verdeeld, hebben we het best passende model ook toegepast op de data van het meest recente productiejaar van de po-indicator. Dit bestand bevat de basisschoolleerlingen van het schooljaar 2020/’21 op basis van peildatum 1 oktober 2020 en de peuters die op 1 oktober 2020 tussen de 2,5 en 4 jaar oud waren. Daardoor kunnen we achterstandsscores voor scholen en gemeenten op basis van de huidige indicator en de herijkte indicator met elkaar vergelijken.
Voor een klein deel van de kinderen is het niet mogelijk om een onderwijsscore uit te rekenen vanwege het ontbreken van één of beide ouders in de Basis Registratie Persoonsgegevens (BRP) of omdat het kind zelf niet in de BRP voorkomt. Bij deze kinderen wordt een onderwijsscore geïmputeerd. Een uitgebreide beschrijving van deze imputatiemethode is te vinden in het vierde methodologische rapport5). Omdat we ook bij de plausibiliteitsanalyses van de achterstandsscores voor scholen en gemeenten in het verleden al hebben gezien dat voor hetzelfde kind de geïmputeerde onderwijsscore van jaar op jaar flink kan veranderen6), lijkt het voor de hand liggend om dit deel van de populatie niet mee te nemen bij de analyses op school- en gemeenteniveau. Echter, deze imputaties zijn niet gelijkmatig over de gehele populatie verdeeld. Sommige scholen of gemeenten kennen een relatief hoog aandeel kinderen waarvan de onderwijsscore is geïmputeerd. Vanwege deze scheve verdeling hebben we voor ieder model ook de onderwijsscores geïmputeerd voor deze kinderen. Daardoor zijn we in staat om op basis van de populatie in het afgelopen schooljaar een volledige simulatie van het effect op school- en gemeenteniveau uit te voeren.
2.2 Gebruikte data voor herijking
Om de vergelijkbaarheid met de huidige indicator te waarborgen gebruiken we voor dit onderzoek dezelfde verrijkte COOL5-18 bestanden als die bij de ontwikkeling van de indicator zijn gebruikt. Deze bestanden bevatten de achtergrondgegevens van alle deelnemende leerlingen die in de schooljaren 2007/2008, 2010/2011 en 2013/2014 in groep 2, 5 of 8 zaten. Uit deze bestanden zullen alleen die leerlingen worden geselecteerd waarvoor in groep 5 een NSCCT-score is opgenomen. Aan deze gegevens zijn uit het SSB de gegevens van de Central Eindtoets van Cito gekoppeld van de betreffende leerlingen in groep 8. Uiteindelijk resulteerde dit in een dataset met gegevens (NSCCT-score, Cito-eindtoetsscore en achtergrondvariabelen) van 19 247 leerlingen. Ter vergelijking: voor het bepalen van de oorspronkelijke po-indicator was een steekproef van 13 466 leerlingen beschikbaar. Het aantal leerlingen steeg doordat nu van meer leerlingen een Cito-eindtoetsscore bekend is dan tijdens eerste onderzoek voor de po-indicator.
Imputaties opleidingsniveau ouders
In het model van de huidige po-indicator zijn de opleidingsniveaus van beide ouders belangrijke voorspellende variabelen voor onderwijsprestaties. Voor kinderen die tot de steekproef behoorden bij de ontwikkeling van het oorspronkelijke model hebben we voor de onbekende opleidingsniveaus, de destijds geïmputeerde opleidingsniveaus overgenomen. Voor de kinderen die zijn toegevoegd aan de onderzoekspopulatie, hebben we in het geval van onbekende opleidingsniveaus deze geïmputeerd met hetzelfde model als bij de ontwikkeling van de oorspronkelijke indicator is gebruikt.
Representativiteit
Om tot een model te komen dat toepasbaar is op de hele populatie van basisschoolleerlingen en peuters is het van belang dat de data een goede afspiegeling vormen van de doelgroep waarvoor het model wordt gebruikt. Uit de technische rapportages van de COOL5-18-onderzoeken wordt duidelijk dat de steekproef representatief is voor de populatie op de basisschool.
Omdat we in dit onderzoek slechts een selectie van de populatie van de COOL5-18-onderzoeken gebruiken – alleen de kinderen die zowel een NSCCT-score in groep 5 als een Cito-eindtoetsscore in groep 8 hebben – hebben we zelf ook nog gekeken naar de representativiteit van de gebruikte selectie.
Om de representativiteit van de uiteindelijk gebruikte steekproef te beoordelen, hebben we gekeken naar in hoeverre de gebruikte selecties uit de drie COOL5-18-onderzoeken onderling overeenkomen. Daarnaast hebben we ook gekeken of er grote afwijkingen zijn met de hele populatie basisschoolleerlingen. Voor deze vergelijking hebben we gekeken naar de opleidingsniveaus van beide ouders en de herkomstcategorie van het kind.
De figuren 2.2.1 en 2.2.2 laten de verdeling van de opleidingsniveaus van de ouders zien (inclusief imputaties). Het is duidelijk te zien dat met name het tweede en het derde COOL5-18-onderzoek vergelijkbaar zijn qua steekproef. In het eerste COOL5-18-onderzoek zijn de hogere opleidingsniveaus iets minder goed vertegenwoordigd, maar echt grote verschillen zijn er niet. Ten opzichte van de verdeling in de data van het meest recente productiejaar van de po-indicator, nemen de lagere opleidingsniveaus een iets groter deel in de steekproef in.
| grp | Basisonderwijs | vmbo-b/k, mbo1 | Vmbo-g/t, avo onderbouw | Mbo2 en mbo3 | Mbo4 | Havo, vwo | Hbo-, wo-bachelor | Hbo-, wo-master, doctor |
|---|---|---|---|---|---|---|---|---|
| 2007 | 11,8 | 16,4 | 5 | 14,9 | 21,3 | 7,7 | 14,6 | 8,3 |
| 2010 | 9,3 | 14,6 | 3,6 | 15,3 | 24,1 | 7,5 | 15,9 | 9,7 |
| 2013 | 8,8 | 14,6 | 4 | 14,1 | 23,3 | 8,3 | 17,5 | 9,5 |
| grp | Basisonderwijs | vmbo-b/k, mbo1 | Vmbo-g/t, avo onderbouw | Mbo2 en mbo3 | Mbo4 | Havo, vwo | Hbo-, wo-bachelor | Hbo-, wo-master, doctor |
|---|---|---|---|---|---|---|---|---|
| 2007 | 14,5 | 13 | 5,9 | 13,6 | 23,7 | 9,6 | 13,8 | 6 |
| 2010 | 10,7 | 11,5 | 5,6 | 13,8 | 26,7 | 8,7 | 14,7 | 8,4 |
| 2013 | 9,6 | 10,3 | 5,5 | 13,5 | 26,9 | 9,1 | 16,6 | 8,6 |
Een andere indicator voor de kwaliteit van de data is de mate waarin het opleidingsniveau van de ouders bekend is. In figuur 2.2.3 is de verdeling hiervan voor de drie COOL5-18-onderzoeken weergegeven. Het is duidelijk te zien dat het aandeel kinderen voor wie van beide ouders het opleidingsniveau bekend is, aanzienlijk toeneemt tussen 2007 en 2013. Het aandeel voor wie van beide ouders het opleidingsniveau onbekend is, neemt daarentegen aanzienlijk af. Omdat ook bij de registraties in het SSB het aantal personen van wie het hoogste opleidingsniveau bekend is toeneemt in de loop van de tijd, is dit in lijn met wat verwacht mag worden.
| grp | Opleidingsniveau beide ouders bekend | Opleidingsniveau moeder onbekend | Opleidingsniveau vader onbekend | Opleidingsniveau beide ouders onbekend |
|---|---|---|---|---|
| 2007 | 18,1 | 15,4 | 18,8 | 47,8 |
| 2010 | 23,9 | 16,4 | 20,5 | 39,3 |
| 2013 | 30,9 | 15,4 | 20,6 | 33,1 |
Als laatste is de verdeling naar herkomst weergegeven in figuur 2.2.4. Zoals is te zien is deze redelijk vergelijkbaar tussen de drie verschillende steekproeven uit de COOL5-18-onderzoeken. Ten opzichte van het meest recente productiejaar van de po-indicator zijn kinderen met een Turkse of Noord-Afrikaanse herkomst enigszins oververtegenwoordigd in de steekproef.
| grp | Nederland | EU-15, andere ontwikkelde economieën | Nieuwe EU-landen en economieën in transitie | Noord-Afrika | Oost-Azië | Overig Afrika, overig Azië, overig Latijns Amerika | Suriname en (voormalige) Nederlandse Antillen | Turkije |
|---|---|---|---|---|---|---|---|---|
| 2007 | 75,9 | 0,9 | 1,3 | 7,8 | 1,2 | 2,8 | 2,7 | 7,3 |
| 2010 | 78,2 | 0,9 | 1,2 | 7,6 | 1,2 | 2,4 | 2,3 | 6,2 |
| 2013 | 76,6 | 1 | 0,9 | 9,3 | 1 | 3,2 | 2,6 | 5,3 |
Concluderend kunnen we zeggen dat de afwijkingen die we zien, geen probleem vormen met betrekking tot de representativiteit van de gebruikte steekproef. Het toevoegen van het derde COOL-onderzoek aan de steekproef lijkt bovendien op alle punten een verbetering: het aandeel ouders met een onbekend opleidingsniveau in de steekproef neemt hierdoor af en de verdeling van opleidingsniveau en herkomst sluit beter aan bij die uit het meest recente productiejaar.
2.3 Toevoegen vertraagd geregistreerde asielzoekers
In de huidige indicator wordt alleen rekening gehouden met asielzoekers en statushouders die tot peildatum 1 oktober van het betreffende schooljaar in de COA- en IND-registraties voorkomen. Omdat er waarschijnlijk vertraging zit in deze registraties, is het wenselijk om te onderzoeken of het meenemen van extra instroomgegevens leidt tot een betere identificatie van asielzoekers en statushouders in het onderzoeksbestand.
Naast het microdatabestand van peildatum 1 oktober 2020 dat eind januari 2021 bij de reguliere productie van de onderwijsachterstandenindicator is gemaakt, zullen de asiel-instroombestanden van de maanden oktober, november en december 2020 worden gebruikt voor deze analyses. In verband met de normale planning van de indicator is het niet zinvol om nog latere instroombestanden te betrekken in de analyses.
Met behulp van deze drie extra asiel-instroombestanden zal per maand bekeken worden hoeveel leerlingen en peuters extra kunnen worden geïdentificeerd als asielzoeker of statushouder. Kanttekening hierbij is wel dat de asiel-instroom als gevolg van de Covid19 crisis aanzienlijk lager is dan normaal. De uitkomsten van deze analyse zullen in dat perspectief moeten worden bezien.
6) Zie de meest recente plausibiliteitsanalyses voor de scholen in het primair onderwijs.