Een meestervervalser helpt bij het herkennen van zonnepanelen

Introductie
Zonnestroom is een belangrijke hernieuwbare energiebron. Het CBS onderzoekt daarom in verschillende projecten hoe de totale opgewerkte zonnestroom in Nederland beter geschat kan worden. Recentelijk schakelde het CBS daarvoor hulp in uit onverwachte hoek: een meestervervalser helpt ons bij het beter herkennen van zonnepanelen op luchtfoto’s.
Het CBS gebruikt bij het herkennen van zonnepanelen in luchtfoto’s zogenoemde deep neural networks. Het herkennen van zonnepanelen op luchtfoto’s lukt goed binnen specifieke afgebakende gebieden waar het neurale netwerk ook is getraind. Een netwerk generaliseren lukt minder goed; het netwerk is niet breed inzetbaar zodat het ook in andere gebieden zonnepanelen goed herkent. Door het netwerk te trainen met een grotere hoeveelheid data is het mogelijk om beter presterende netwerken te maken. Hier zijn grote hoeveelheden plaatjes voor nodig. Deze plaatjes worden handmatig—vaak door meerdere mensen—beoordeeld of ze wel of geen zonnepanelen bevatten. Dit is een arbeidsintensief traject. De vraag is daarom: is het ook mogelijk om plaatjes toe te voegen zonder dat mensen deze hebben beoordeeld? Het CBS heeft onderzoek gedaan naar zogenaamde Generative Adversarial Networks (GANs); neurale netwerken die automatisch nieuwe plaatjes kunnen maken.
Welke plaatjes hebben de grootste toegevoegde waarde?
Om automatisch nieuwe plaatjes aan te maken is het eerst nodig om plaatjes te kunnen herkennen die veel op elkaar lijken. Hiervoor wordt gezocht naar patronen of clusters in de achterliggende data. Het ontdekken van patronen in data kan met verschillende technieken. Dit onderzoek richtte zich op twee typen clustering methoden: k-means en agglomerative clustering.
Het bleek dat k-means betere resultaten opleverde dan agglomerative clustering. K-means deelde de data op in vijf clusters: vier clusters met overwegend plaatjes met zonnepanelen en één cluster met overwegend plaatjes zonder zonnepanelen. De clusters bevatten een grote diversiteit aan plaatjes en vormen een goede basis voor het genereren van verschillende soorten kunstmatige plaatjes.
De clusters kunnen in meer detail worden bekeken met T-distributed Stochastic Neighbor Embedding (t-SNE), een methode die hoog dimensionale ruimten kan visualiseren. Een dergelijke visualisatie kan een beter idee geven van de plaatjes in het cluster en hoe deze zich ten op zichtte van elkaar verhouden.
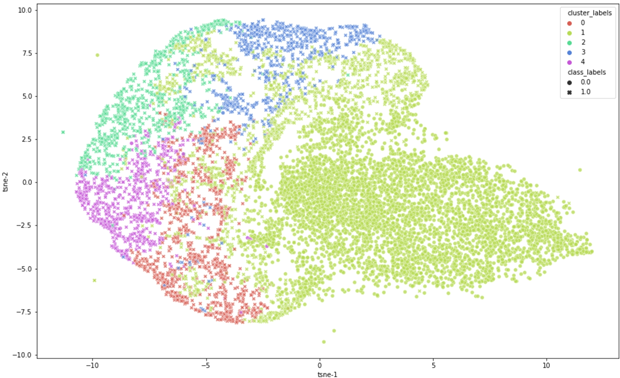
Een t-SNE visualisatie van de clusters in de trainingsset.
Bovenstaande figuur geeft de t-SNE visualisatie weer van de door k-means afgeleide clusters in het training set. Het valt op dat de clusters met overwegend positieve samples (0, 2, 3, 4) redelijk goed van elkaar gescheiden zijn. Daarentegen overlappen relatief veel plaatjes in cluster 1 (lichtgroen), het cluster met overwegend negatieven (= geen zonnepanelen), met de andere clusters. Uit een nadere analyse blijkt dat cluster 1 rond de 25 procent positieven bevat. Bijna 50 procent van die positieven blijkt ook nog eens verkeerd te zijn geclassificeerd. In dit cluster zitten dus plaatjes waarvan het netwerk maar moeilijk kan bepalen of er wel of geen zonnepaneel op staat. Door specifiek plaatjes toe te voegen waar het netwerk nog moeite mee heeft, kan het netwerk hopelijk worden verbeterd.
Generative Adversarial Networks
Een generative adversarial network (GAN) is een specifiek deep neural network dat uit twee componenten bestaat. De eerste component is de generator of vervalser die probeert plaatjes (vervalsingen) te genereren die moeilijk van echt zijn te onderscheiden. De tweede component is de discriminator die de vervalste plaatjes juist van de echte moet onderscheiden. Beide delen worden samen getraind met als einddoel een GAN die vervalsingen oplevert die moeilijk van echt te onderscheiden zijn.
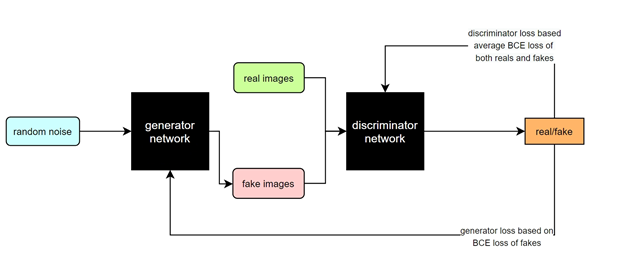
Voorbeeld van een GAN met BCE loss functie. De generator creëert vervalsingen, de discriminator probeert onderscheid te maken tussen echte plaatjes en deze vervalsingen.
Resultaten
Het trainen van GANs duurt vaak meerdere dagen. Het instellen van de parameters is grotendeels handmatig werk en luistert heel nauw. Toch is het gelukt om voldoende bruikbare GANs op te leveren die elk goede vervalsingen konden genereren. Onderstaande figuur toont de resultaten van één zo’n GAN met voor elke rij genereerde plaatjes voor één van de clusters die als invoer diende.

Voorbeeldplaatjes die door een GAN gemaakt zijn. Duidelijk zijn hierop de vervalste zonnepanelen te zien.
Het onderzoek evalueerde verschillende GANs, zowel kwalitatief als kwantitatief. De kwalitatieve evaluatie omvat een visuele inspectie en is daardoor subjectief. De kwantitatieve evaluatie gebruikt twee maatstaven: (1) de Fréchet Inception Distance, een afstandsmaat die de overeenkomst van twee plaatjes evalueert en (2) de verbetering van de classificatiemetrieken als er gegenereerde plaatjes worden toegevoegd bij het trainen van het model.
Er zijn vier typen GANs getraind en geëvalueerd. Elk type GAN leverde bruikbare plaatjes op. De beste plaatjes werden gegeneerd door de zogenoemde Wasserstein GAN. Voor dit type model was de Fréchet Inception Distance het kleinst en de plaatjes dus van de hoogste kwaliteit. Daarnaast verbeterde de prestatie van het classificatiemodel het meeste na het toevoegen van de door het Wasserstein-model gegenereerde plaatjes.
Om dit te evalueren werd eerst een model getraind op de originele trainingsset. Daarna werd hetzelfde model met dezelfde parameters getraind op een trainingsset met extra door de GAN gegenereerde plaatjes. Vervolgens werden beide modellen geëvalueerd op een testset. Voor het evalueren werden de accuracy, recall en precision gebruikt. Bij alle succesvolle GANs namen de accuracy en recall 2 tot 3 procent toe. In het beste geval, de Wasserstein GAN, was de toename 6 procent. In alle gevallen ging deze verbetering ten koste van de precision, maar die bleef hoog met waardes boven de 92 procent.
Conclusie
Generative adversarial networks (GANs) kunnen succesvol ingezet worden bij het genereren van extra trainingsdata en de verbetering van classificatiemodellen. Ze zijn dus een goed extra hulpmiddel wanneer gelabelde data moeilijk te verkrijgen of kostbaar is. Ook kunnen ze gebruikt worden om data uit een bepaalde klasse of van een bepaald type te genereren. GANs kunnen plaatjes uit een andere regio of domein genereren, zonder dat daarbij veel plaatjes handmatig geannoteerd moeten worden. Dit is een interessante onderzoeksrichting die in de toekomst zeker meer aandacht verdiend.
Erkenning
Dit onderzoek is uitgevoerd in het kader van een stageopdracht in samenwerking met de Universiteit Maastricht.
Downloads
- PDF Paper - Addressing the class imbalance in aerial images
Relevante links
- Link Nieuwsbericht - Zonnepanelen automatisch detecteren met luchtfoto’s