Deep learning voor de detectie van zonnepanelen

Introductie
Zonnestroom is een belangrijke hernieuwbare bron. CBS doet daarom in verschillende projecten onderzoek waarmee we de schatting van de totale opgewerkte zonnestroom in Nederland kunnen verbeteren. Een van deze projecten is Deep Solaris. In dit project hebben we verschillende Deep Learning methoden geëvalueerd om het herkennen van zonnepanelen in luchtfoto's te automatiseren.
Deep Solaris
In het DeepSolaris project is onderzocht of het mogelijk is om modellen te trainen die voor heel Europa toepasbaar zijn. Met onze partners Statbel in België, IT.NRW en Destatis in Duitsland en de Open Universiteit Nederland hebben we onderzocht of modellen die op het ene land werden getraind ook op het andere land konden worden toegepast. De focus lag op de Euregio (provincie Limburg, Vlaanderen en Noordrijn-Westfalen). Voor Limburg en Noordrijn-Westfalen waren de hoogste resolutie foto’s beschikbaar (10 cm per pixel). Voor beide gebieden hebben we hiervoor de luchtfoto van 2018 gebruikt, alsmede aanvullende registerdata. In Nederland bestond deze registerdata uit gegevens gebaseerd op het PIR en de BTW aangifte. In Noordrijn-Westfalen was het LANUV register (Landesamt für Natur, Umwelt und Verbraucherschutz Nordrhein-Westfalen; oftewel de organisatie voor Natuur-, Milieu- en Consumentenbescherming van de staat Noordrijn-Westfalen) beschikbaar. Beide registers bevatten de addressen en ook de geolocaties van de zonnepanelen die voor het specifieke geografische gebied bekend zijn.
Trainen en evalueren
We richten ons in dit artikel op het classificatiemodel dat getraind en geëvalueerd werd op regio Zuid Limburg. We hebben hiervoor het VGG16 deep learning model gebruikt van de Visual Geometry Group van de Universiteit Oxford. Het model werd hiertoe aangepast voor ons specifiek doel om zonnepanelen te identificeren en vervolgens getraind via zogenoemde 'transfer learning' met foto uitsnedes van 200x200 pixels (20m bij 20m) voor regio Heerlen. Om te evalueren hoe goed het getrainde algoritme presteert, hebben we uitsnedes uit de regio Valkenburg (het heuvelland) gebruikt.
Eén manier waarop we de prestatie van het model kunnen evalueren is door het te vergelijken met de beschikbare register data en de door mensen gegeven labels (de annotaties). Zo wordt duidelijk waar het model een correcte voorspelling geeft en waar het model een incorrecte voorspelling geeft.
Vergelijking met de beschikbare register data en annotaties
Om te weten te komen hoe goed het getrainde model de aanwezigheid van zonnepanelen op een foto voorspelt, kunnen we deze voorspelling vergelijken met de informatie in de registers en met door mensen gemaakte annotaties. Dit is wel iets complexer dan het op het eerste gezicht misschien lijkt. Uit de register data kan bijvoorbeeld worden afgeleid op welk adres een zonnepaneel installatie aanwezig is. Dit adres kan echter op meerdere foto uitsnedes voor komen als het een groot pand is of als het precies op de rand van een foto staat. Andersom geldt dat op een foto meerdere adressen kunnen voorkomen. De resultaten van een foto (wel of geen zonnepanelen) kunnen dus niet 1-op-1 met de register informatie worden vergeleken.
Voor de menselijke annotaties geldt dat de kwaliteit daarvan afhankelijk is van de persoon die de annotaties uitvoert en de zichtbaarheid van de zonnepanelen in de uitsnedes. Zo kunnen in een onoplettend moment zonnepanelen over het hoofd gezien worden of is het in sommige gevallen moeilijk te bepalen of er zonnepanelen in de uitsnede aanwezig zijn; denk hier bijvoorbeeld aan een foto met veel schaduw of een dakraam dat heel erg op zonnepanelen lijkt. In het ideale geval zou een uitsnede door meerdere mensen geannoteerd moeten worden en zou je moeten bepalen wanneer er voldoende zekerheid is dat er op de foto een zonnepaneel staat. Hoeveel mensen zijn hiervoor nodig en hoeveel daarvan moeten het met elkaar eens zijn? De laatste complicatie tenslotte is dat het model ook geen discrete keuze maakt tussen zonnepaneel/geen zonnepaneel. Het model levert in plaats daarvan waarden tussen 0 en 1 op en er moet dus een afkapwaarde gekozen worden waaronder we aannemen dat er geen zonnepanelen in de uitsnede aanwezig zijn, en waarboven we aannemen dat er wel zonnepanelen aanwezig zijn.
Om per uitsnede een directe vergelijking te maken, moeten er dus bepaalde aannames gemaakt worden. Zo hebben we aangenomen dat de door mensen gemaakte annotaties correct zijn. We vergelijken dus zowel de voorspelling als de register data met deze annotaties. Om een register label toe te kennen aan elke uitsnede, hebben we ervoor gekozen om de fractie van het gebouw met de zonnepanelen te gebruiken. We hebben hiervoor een afkapwaarde gekozen die deze register labels zoveel mogelijk laat overeenkomen met de labels van de annotaties. Voor het model hebben we een afkapwaarde van 0.5 gebruikt.
Op basis van deze aannames worden in het onderstaande figuur de voorspellingen van het model vergeleken met het uit het register afgeleide label en tegelijkertijd met de door mensen gemaakt annotaties. Bij een overeenkomst tussen alle labels kunnen we ervan uitgaan dat ze alledrie kloppen. Zoals in onderstaande figuur te zien is komen de labels in bijna 88% van de gevallen overeen. Het grootste deel van de labels (rond de 43000) is negatief, ongeveer 3500 labels zijn positief. In ongeveer 12% van de gevallen wijkt één van de drie labels af. Er zijn dus drie verschillende mogelijkheden te onderscheiden waarin één van de categorieën afwijkt van de andere twee:
- De annotatie en het register label zijn hetzelfde, maar de model voorspelling verschilt (4,75% in het onderstaande diagram)
- De annotatie en de model voorspelling zijn hetzelfde, maar het register label verschilt (5.36% in het onderstaande diagram)
- Het register label en de model voorspelling zijn hetzelfde, maar de annotatie verschilt (1.91% in het onderstaande diagram)
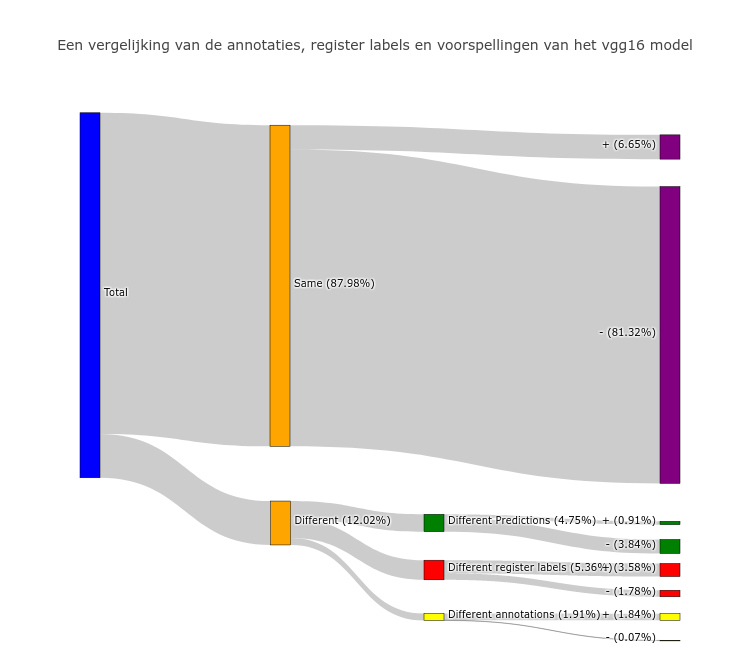
Voor de eerste categorie waarin de model voorspellingen verschillen van de annotaties en de register labels, zien we dat het model hier in overgrote meerderheid (3.84% ten op zichte van 0.91% van het totaal) een negatief label voorspelt. Het model heeft dus een neiging om meer negatieve voorspellingen te geven. Als we door de mensen gegeven labels kijken zien we dat de meerderheid van de annotaties met elkaar in overeenstemming zijn. In het grote merendeel van de gevallen zal het model hier dus fout zitten. Omdat het hier in het algemeen gaat om uitsnedes met een positief label, is het interessant om te zien waarom het model hier een verkeerde voorspelling maakt. Om het model in de toekomst beter met deze uitsnedes om te laten gaan, kan het model verder getraind worden waarbij deze specifieke uitsnedes een groter gewicht gegeven wordt of waarbij ze vaker aan het model worden aangeboden.
Voor de tweede categorie waarbij het register label afwijkt van de andere labels, zien we dat het register label hier overwegend positief is (3.58% ten op zichte van 1.78% van het totaal). Ook hier geldt weer dat het merendeel van de mensen het met elkaar eens waren over het annotatie label. De positieve categorie is interessant omdat het hier kan gaan om uitsnedes waar op basis van het register een positief label aan gegeven is. Aan de ene kant kan het gaan om een gebouw met zonnepanelen waar deze zonnepanelen in een andere uitsnede liggen. Aan de andere kant kan het gaan om addressen in het register waar niet langer zonnepanelen aanwezig zijn. De negatieve categorie is interessant omdat het hier kan gaan om zonnepanelen die in het register ontbreken.
Voor de laatste categorie geldt dat zowel het register als de model voorspellingen verschillen van de annotatie. Een meerderheid van de annotatie labels is positief (1.84% positieve ten opzichte van 0.07% negatieve van het totaal). In het grote merendeel van de gevallen (885/1006) gaat het hier om annotaties waarvan de mensen die de uitsnede geannoteerd hebben het met elkaar eens zijn. In de overige gevallen (121/1006) geldt dat er een grote onenigheid is over de correcte annotatie. Het gaat hier dus om uitsnedes waarop moeilijk te zien is of er zich daadwerkelijk zonnepanelen op bevinden. Er zijn hier dus meerdere interpretaties mogelijk. Enerzijds kan het gaan om een incorrecte annotaties. Het register label en het model geven hier extra informatie die in het geval van moeilijk te interpreteren uitsnedes toch een label aan de uitsnede kunnen geven. Anderzijds kan het ook zijn dat zowel de model voorspellingen als het register label hier fout zijn. Deze laatste categorie is met name interessant omdat het grootste deel van de annotaties positief zijn en het dus kan gaan om zonnepanelen die niet aanwezig zijn in het register.
De negatieve register labels uit de tweede categorie en de positieve annotatie labels in de derde categorie geven informatie over installaties die mogelijk ontbreken in het register. Omdat de luchtfoto van 2018 gedurende een groot deel van het voorjaar en de zomer wordt genomen en daarom niet precies te achterhalen is wanneer welk deel van de foto genomen is, hebben we de hoge resolutie foto van 2018 vergeleken met de registerdata tot eind december 2017 alsmede de lage resolutie luchtfoto van 2017. We hebben deze vergelijking alleen gemaakt voor de hierboven genoemde regio’s in Zuid Limburg. Panelen die in 2018 gevonden zijn, niet in het register en niet op de luchtfoto van 2017 voorkomen zijn dan geheel nieuwe panelen. Panelen die in 2018 gevonden zijn, niet in het register voorkomen maar daarentegen wel op de luchtfoto van 2017 te zien zijn, zijn panelen die niet in het register zijn opgenomen. Andersom kan ook, er kunnen panelen in het register opgenomen zijn die niet op de luchtfoto te zien zijn. Het kan hier echter ook gaan om panelen die bijvoorbeeld bij een verhuizing van het dak zijn afgehaald. Tijdens deze analyse werden er 760 nieuwe zonnepanelen ontdekt die nog niet in het register van 2017 voorkwamen. Deze panelen zijn er dus in eind 2017, na het nemen van de luchtfoto, of in 2018 bijgekomen. Tevens werden er 449 zonnepanelen ontdekt die zowel op de luchtfoto van 2018 als op de luchtfoto van 2017 voorkwamen, maar ontbraken in het register.
Voorlopige Conclusie
Uit de resultaten blijkt dat het mogelijk is om met deep learning technieken, specifiek het VGG16 model, zonnepanelen te herkennen in luchtfoto’s. Er kunnen met behulp van deze modellen ook zonnepanelen worden ontdekt die niet in de registers voorkwamen. Met behulp van deze modellen, toegepast op de luchtfoto’s, kunnen dus bestaande registers worden verrijkt. Deep learning modellen zijn dus een interessant gereedschap voor de officiële statistiek, maar voordat dit gereedschap gebruikt kan worden, moeten er nog een aantal vragen worden beantwoord.
Wordt vervolgd
Ook al is het DeepSolaris project afgelopen, het onderzoek naar de detectie van zonnepanelen in luchtfoto’s zal binnen het CBS worden voortgezet. Om officiële statistiek te maken uit Deep Learning algoritmen moet er gekeken worden naar de hele keten van dataset, annotatie, model tot voorspelling en uiteindelijk statistiek. Bij het trainen en evalueren van een model is het ten eerste belangrijk dat het dataset een goede weergave is van de werkelijkheid; een dataset moet een goede steekproef zijn van de gehele populatie. Ook de kwaliteit van de annotaties is belangrijk: door elke annotatie door meerdere personen te laten uitvoeren kan er iets gezegd worden over de zekerheid van deze annotaties. Daarnaast zal er gekeken worden naar de robuustheid en betrouwbaarheid van de modellen; hoe goed werkt een model getraind op Zuid Limburg boven de Randstad. Ook willen we kijken naar alternatieve metrieken voor het evalueren van de prestatie van de modellen. Maten als precision, accuracy en de F1-score worden sterk beïnvloed door een onbalans in de dataset. Omdat het aantal huizen met zonnepanelen in Nederland nog altijd veel kleiner is dan het aantal huizen zonder zonnepanelen hebben we te maken met een sterke onbalans in de datasets. Door metrieken te gebruiken die deze onbalans in ogenschouw nemen, kunnen we een eerlijkere en meer betrouwbare meting geven van de prestatie van onze modellen. Als laatste willen we ook gaan kijken naar object detectie modellen, waarmee de locatie, grootte en het aantal panelen kunnen worden afgeleid. Op basis van deze gegevens kunnen we meer gedetailleerde statistieken maken dan op basis van de classificatiemodellen.
Privacy maatregelen
Het CBS publiceert gegevens altijd zodanig dat daaraan geen herkenbare gegevens over een afzonderlijk persoon, huishouden, onderneming of instelling kunnen worden ontleend. Hoewel in dit project openbare gegevens (luchtfoto’s, satellietbeelden) als basis voor de analyse worden gebruikt, zullen de interactieve kaarten enkel op geaggregeerd niveau aantallen zonnepanelen laten zien.
Erkenning
Dit onderzoek wordt uitgevoerd onder de ESS actie 'Merging Geostatistics and Geospatial Information in Member States' (grant agreement no.: 08143.2017.001-2017.408) en een CBS investering voor de ontwikkeling van een Deep Learning algoritme. Voor meer informatie over de inspanningen die CBS verricht om haar zonnestroom statistiek te verbeteren, zie de publicatie ‘Slim zonnestroom in kaart brengen’ en de publicatie ‘Zonnepanelen automatisch detecteren met luchtfoto’s‘.